 Text is nothing more than unstructured data. When you consider how much textual data your enterprise organization has – or has access to – it’s no surprise that 90% of your data isn’t analyzed.
Text is nothing more than unstructured data. When you consider how much textual data your enterprise organization has – or has access to – it’s no surprise that 90% of your data isn’t analyzed.
Traditional analytics can only analyze structured data. But no matter how much information your organization has stored in tables, rows, and columns, it’s not the whole picture. Most of your data is unstructured, textual data.
The key to better data-driven decisions is tapping into all of your data – and not just the data in rows and columns. To make that happen, you need a data platform that connects your structured and unstructured data, allowing you to analyze fluidly across all sources and silos.
GraphGrid makes this next-level analysis possible through the power of Natural Language Processing (NLP). The NLP service helps you combine the structured data you already have along with the unstructured text data that you haven’t been fully utilizing. The result is a new structure of connected data stored in the context of a knowledge graph (which in turn is backed by a native graph database).
Let’s take a closer look at the full capabilities of using Natural Language Processing with GraphGrid.
Core Capabilities of GraphGrid NLP
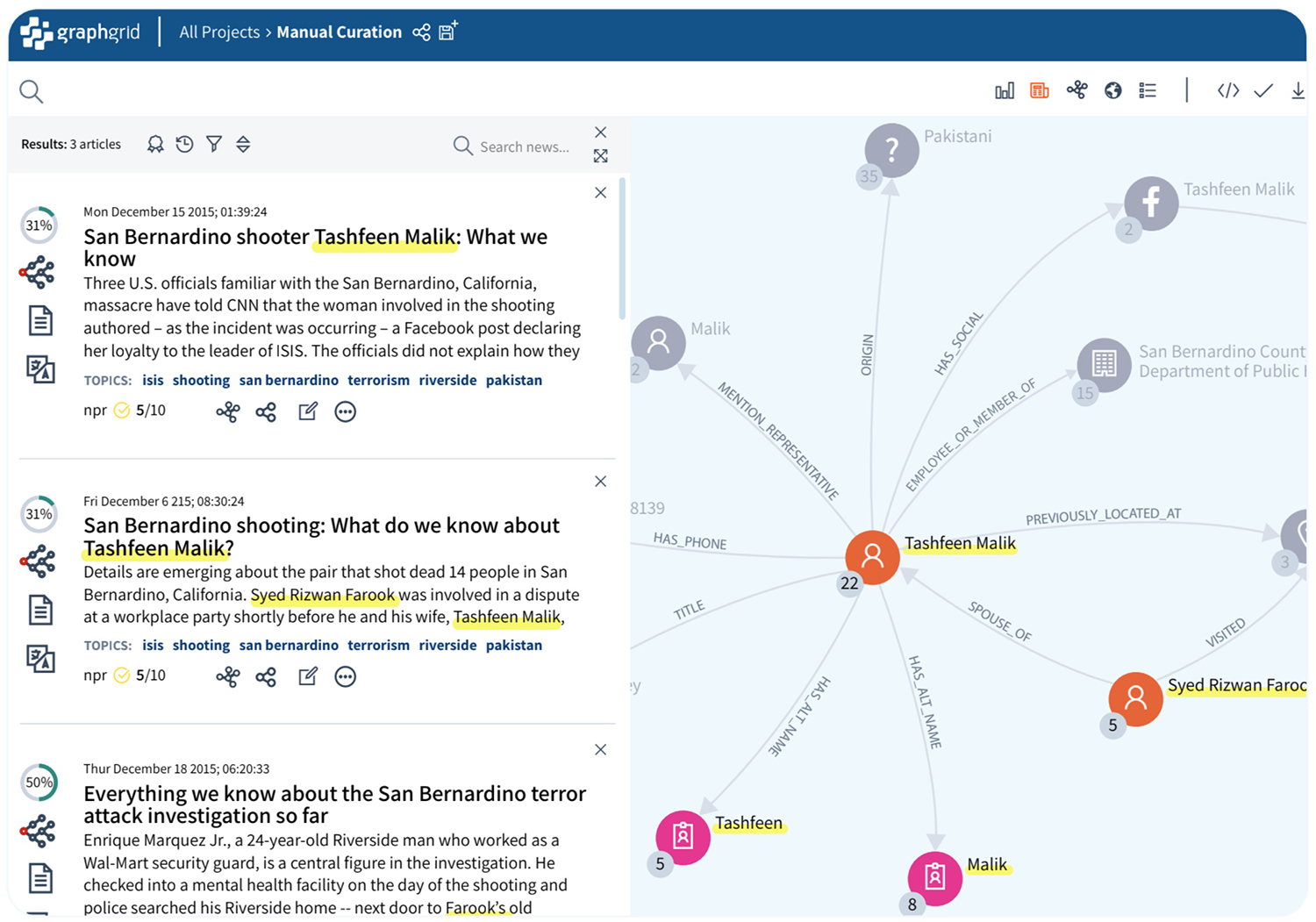
GraphGrid NLP uses text-to-graph data extraction and various other natural language processing features. This NLP extraction forms a framework of tools for real-time text processing.
Here are some of the top NLP tools available to you right out of the box:
- Data extraction turns your document text into nodes and relationships within a graph data structure. This tool is the basis for GraphGrid NLP’s other language processing features. Data extraction captures natural language and makes it available for all sorts of data analysis, adding depth to your insights.
- Document similarity scoring compares and contrasts two documents to understand better if, how, and in what ways they are related to each other. GraphGrid NLP uses the Term Frequency-Inverse Document Frequency (TF-IDF) method for similarity scoring between documents.
- Document summarization automatically summarizes documents based on their most relevant sentences as calculated by the average of its word’s TF-IDF score.
- Document origination is a form of data lineage that creates and maintains an ordered list or story arc identifying which documents come from one another.
- Paraphrase detection translates two documents into sentence vectors and compares them to determine how closely related (or not) they are.
- Named Entity Recognition (NER) identifies people, locations, and organizations within a given text sample.
- Relationship extraction determines how people, places, and things (identified by NER) are related and interconnected.
- Keyphrase extraction pinpoints concepts associated with particular nodes within the graph data structure of your given text.
These tools let you take any text and turn it into meaningful, connected data. To dive deeper into GraphGrid NLP capabilities, check out the NLP documentation (plus the NLP model training docs) or start with the GraphGrid NLP Basics tutorial.
NLP That Keeps Up with Your Data
Analyzing textual data isn’t new. Many tools and platforms harness the power of Natural Language Processing to evaluate textual data. However, since most tools use rigid data structures, data extraction can often be a lengthy process completed in overnight batches. And once processed, textual data still requires costly database migrations to merge the new data with the existing structured data.
In the meantime, conditions might change, and your mission-critical decisions end up based on stale intel. This scenario is the opposite of data-driven decision-making.
Fortunately, GraphGrid NLP uses continuous processing to turn today’s news into today’s data. Continuous processing means GraphGrid automatically ingests new data sources into the graph database and updates your real-time insights based on the new data. (Look out for more information on GraphGrid data ingestion in a future article.)
Another consideration for real-time decision-making – especially when it comes to textual data – is that the information you need most might not be in English.
Enterprise organizations with a global reach might need to ingest Russian or Portuguese data to stay up to date on key customers, stakeholders, or partners. That’s why GraphGrid NLP service is available in 10 languages, including:
- English
- Arabic
- Chinese
- French
- German
- Japanese
- Korean
- Portuguese
- Russian
- Spanish
Conclusion
If your organization is like many others, you’re likely overlooking 90% of your data because it’s stored as text and not tables. The Natural Language Processing service with GraphGrid Connected Data Platform unlocks your unstructured data and adds necessary context to your existing structured data.
Bottom line: You have the data you need to make well-informed decisions.
See it in action:
Download GraphGrid and try out NLP on your own documents and data.